Networks used usually for computer vision, they use convolutional layers that exploit the visual domain traslation invariance (for a motivationConvolutions from first principles), and hierarchical structer of the visual world by stacking layers and lateyers, with the idea that each layer learing more complex feature.
They also implement pooling, a way to reduce the input size.
The typical architercure is stacking conv. layerse and then pooling to reduce the size, in the end a flatten and a dense network to output classes.
The convolution layer
The layer learns the weights for a filter (or conv. kernel). You need to set the size of this windows, the stride, padding for boundary conditions, and the number of kernels (the idea is that you want to extract different features simultaneously.)
Examples
LetNet-5 for MNIST
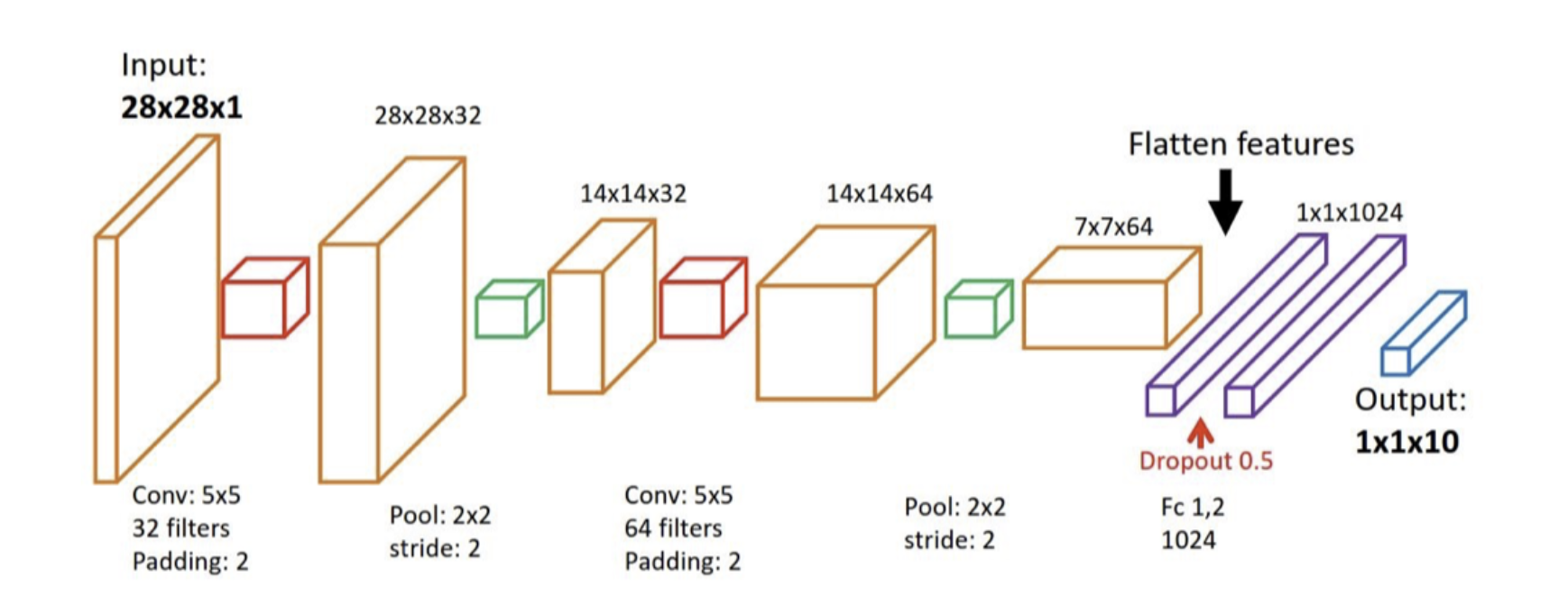
- convolutional layers, num_filters =
- dense layers
- average pool
AlexNet
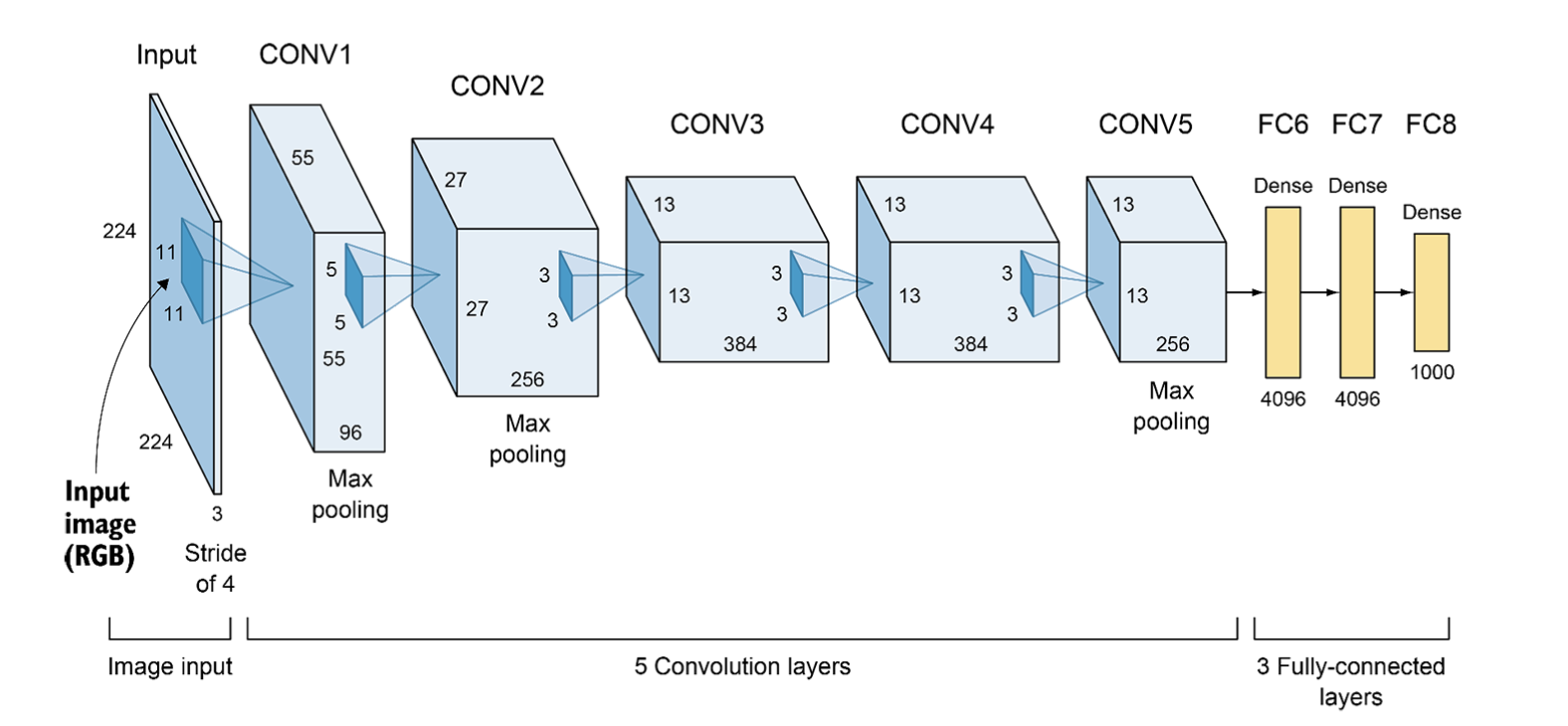
- much bigger input size, ImageNet competition
- conv. layers
- max pooling
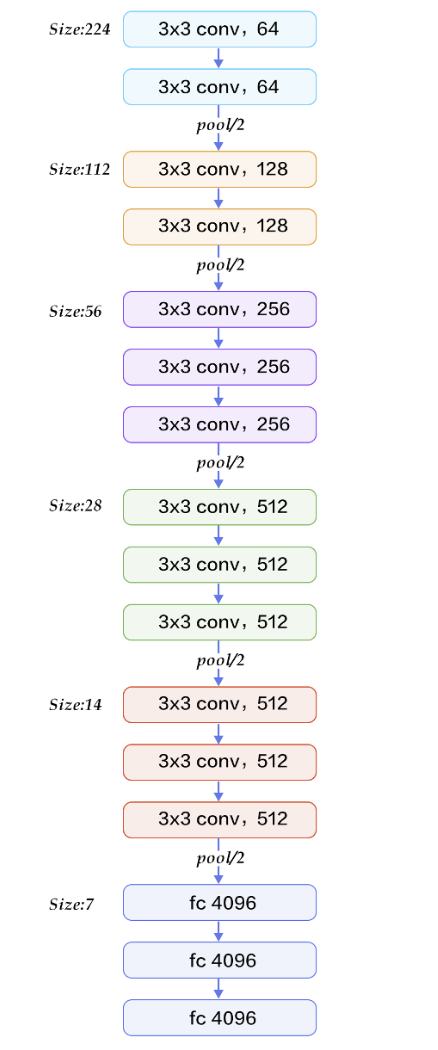
VGG-16
GoogleLeNet
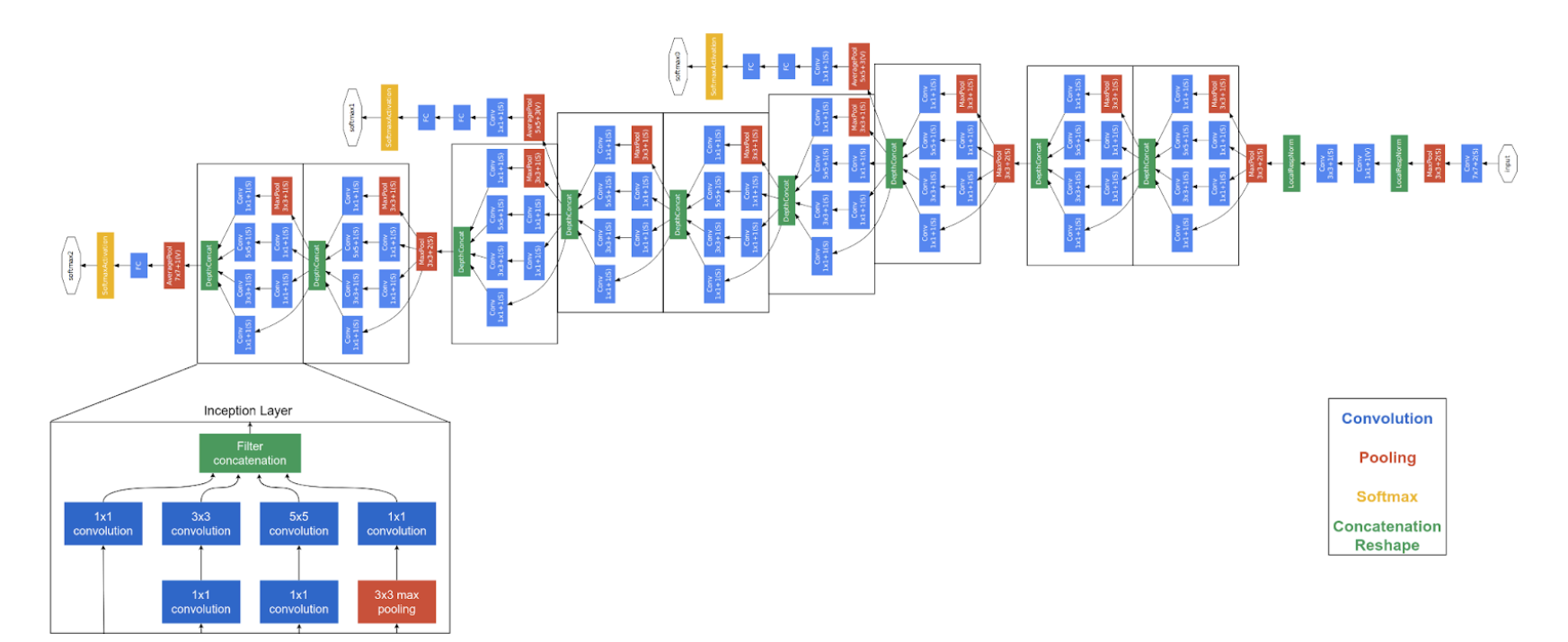
- very deep: layers
- adding two more outputs, their loss in added weighted by , ignored at inference.
ResNet
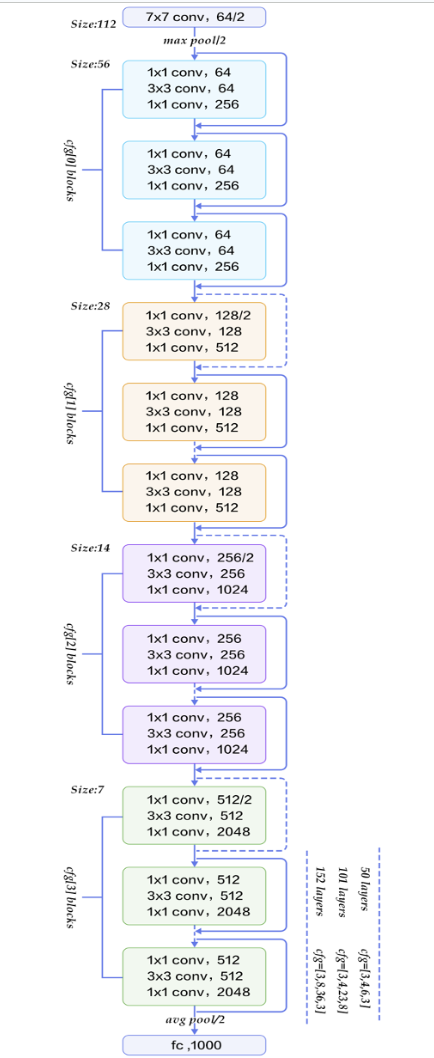
- deep
- added residuals!