Encoder Converts an input sequence of tokens into a sequence of embedding vectors, often called the hidden state or context. Decoder Uses the encoder’s hidden state to iteratively generate an output sequence of tokens, one token at a time.
The Encoder-Decoder framwork is used for tasks where the input and output vary in size, an example is manchine translation. Prior to Transformers the state of the art model were LSTMs.
The job of the encoder is to encode the information from the input sequence into a numerical representation that is often called the last hidden state. This state is then passed to the decoder, which generates the output sequence.
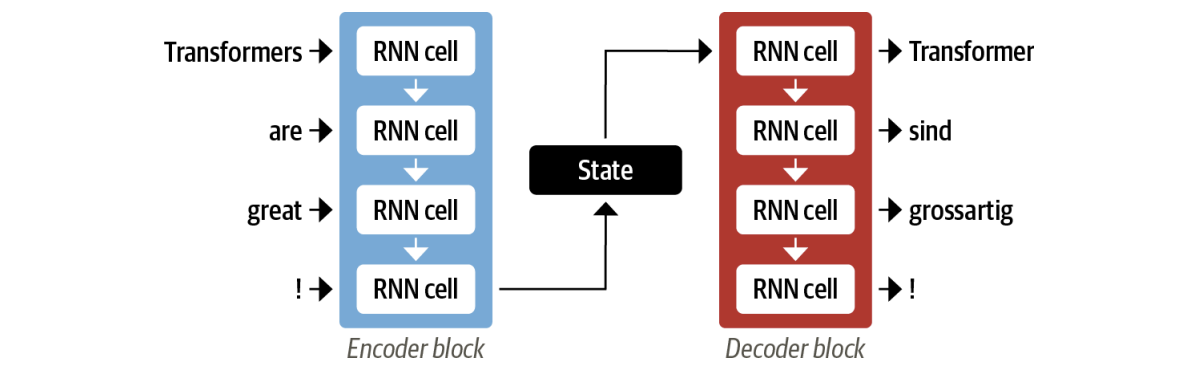 One weakness of this architecture is that the final hidden state of the encoder creates an information bottleneck, this is especially challenging for long sequences, where information at the start of the sequence might be lost in the process of compressing everything to a single, fixed representation.
One weakness of this architecture is that the final hidden state of the encoder creates an information bottleneck, this is especially challenging for long sequences, where information at the start of the sequence might be lost in the process of compressing everything to a single, fixed representation.
A way out of this bottleneck by allowing the decoder to have access to all of the encoder’s hidden states. The general mechanism for this is called Attention mechanism, (it was developed for RNNs!).