The Transformer Architecture
The original Transformer is based on the encoder-decoder architecture.
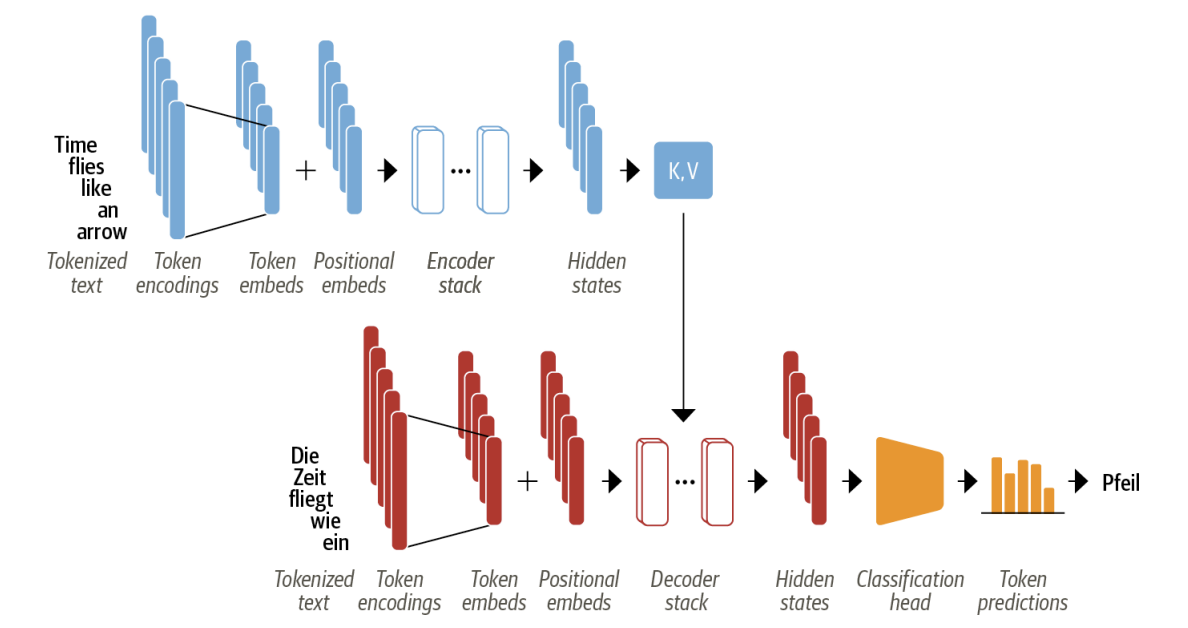
- The input text is tokenized and converted to token embeddings. Since the attention mechanism is not aware of the relative positions of the tokens, we need a way to inject some information about token positions into the input to model the sequential nature of text. The token embeddings are thus combined with positional embeddings that contain positional information for each token.
- The encoder is composed of a stack of encoder layers or “blocks,” which is analogous to stacking convolutional layers in computer vision. The same is true of the decoder, which has its own stack of decoder layers.
- The encoder’s output is fed to each decoder layer, and the decoder then generates a prediction for the most probable next token in the sequence. The output of this step is then fed back into the decoder to generate the next token, and so on until a special end-of-sequence (EOS) token is reached. We repeat the process until the decoder predicts the EOS token or we reached a max‐ imum length.
There are variants of transformers:
Encoder-only These models convert an input sequence of text into a rich numerical representa‐ tion that is well suited for tasks like text classification or named entity recogni‐ tion. BERT and its variants, like RoBERTa and DistilBERT, belong to this class of architectures.
Decoder-only Given a prompt of text like “Thanks for lunch, I had a…” these models will auto-complete the sequence by iteratively predicting the most probable next word. The family of GPT models belong to this class. The representation computed for a given token in this architecture depends only on the left context. This is often called causal or autoregressive attention.
The Encoder
the transformer’s encoder consists of many encoder layers stacked next to each other. Each encoder layer receives a sequence of embeddings and feeds them through the following sublayers:
- A multi-head self-attention layter
- A fully connected feed-forward layer
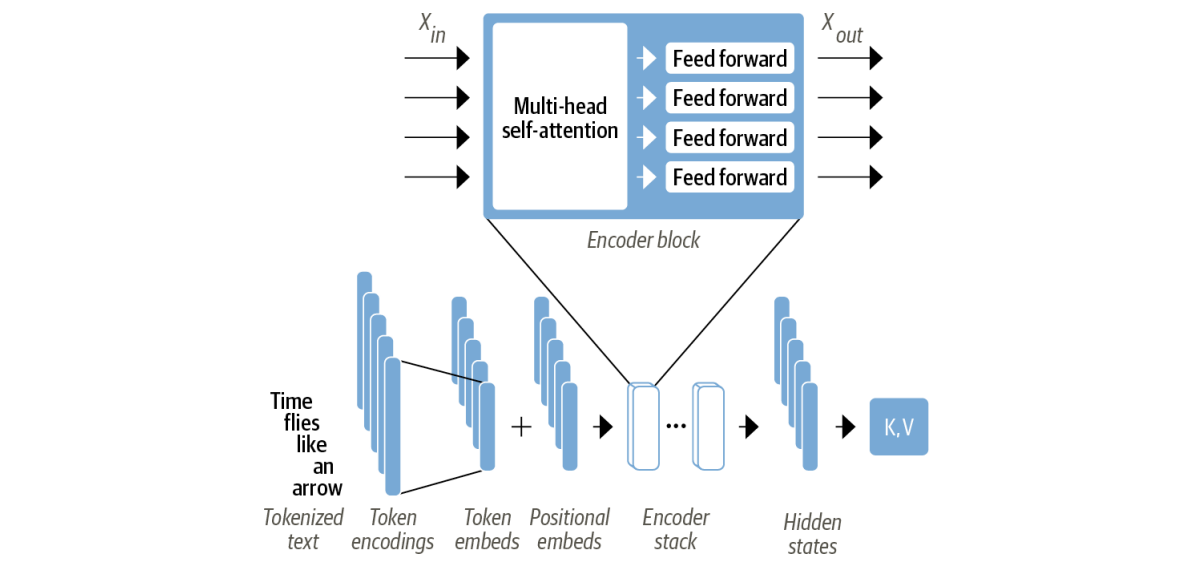
the intuition is that after every encoder block the input embeddings are updated to produce better representaiton, for example the word “Apple” will be updated to be more “company-like” insted of “fruit-like” if in the context there are words like “phone” and “keynot”.