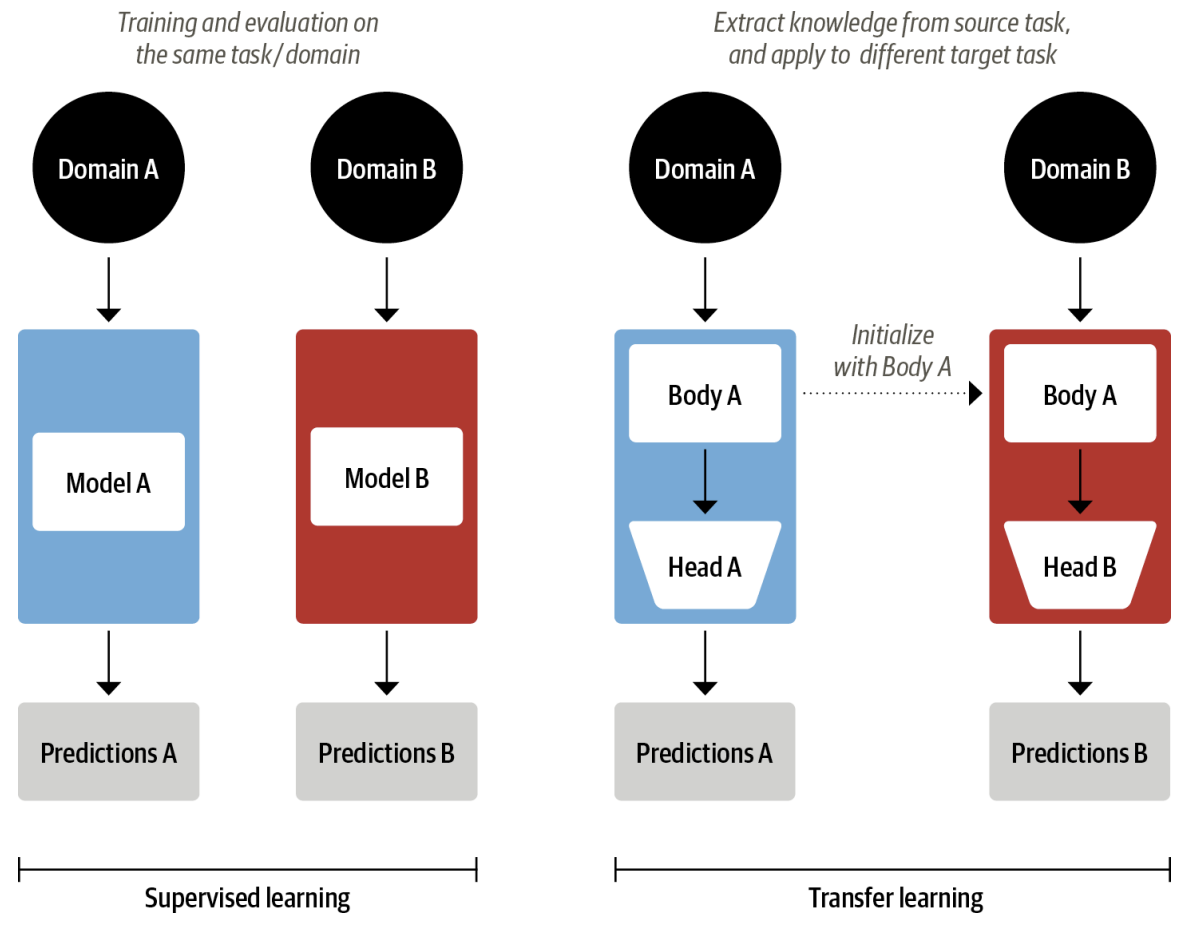
Fine-tuning In computer vision, it is common practice to use transfer learning to train a convolutional neural network like ResNet on one task and then adapt it to or fine-tune it on a new task.
Architecturally, this involves splitting the model into a body and a head, where the head is a task-specific network.
During training, the weights of the body learn broad features of the source domain, and these weights are used to initialize a new model for the new task. Compared to traditional supervised learning, this approach typically produces high-quality models that can be trained much more efficiently on a variety of downstream tasks, and with much less labeled data.
In computer vision, the models are first trained on large-scale datasets such as Image‐Net, which contain millions of images. This process is called pretraining and its main purpose is to teach the models the basic features of images, such as edges or colors. These pretrained models can then be fine-tuned on a downstream task such as classifying flower species with a relatively small number of labeled examples (usually a few hundred per class). Fine-tuned models typically achieve a higher accuracy than supervised models trained from scratch on the same amount of labeled data.
In 2017 and 2018, several research groups (stared from OpenAI) proposed new approaches that finally made transfer learning work for NLP.
The ULMFiT process
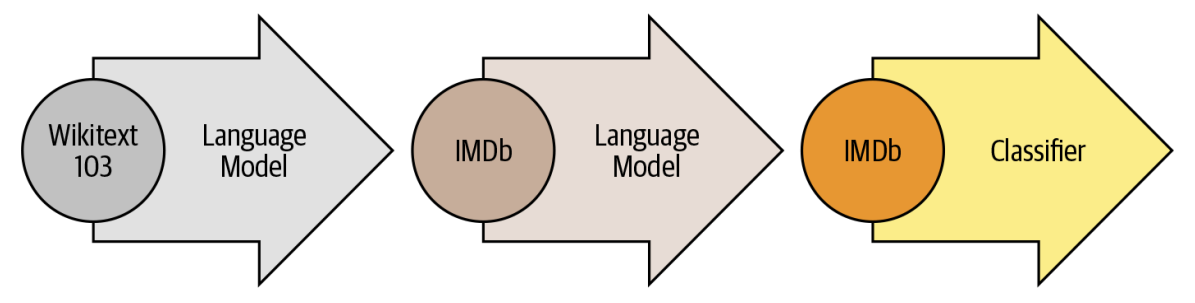
- Pretraining The initial training objective is quite simple: predict the next word based on the previous words. This task is referred to as language modeling. The elegance of this approach lies in the fact that no labeled data is required, and one can make use of abundantly available text from sources such as Wikipedia.
- Domain adaptation Once the language model is pretrained on a large-scale corpus, the next step is to adapt it to the in-domain corpus (e.g., from Wikipedia to the IMDb corpus of movie reviews, as in Figure 1-8). This stage still uses language modeling, but now the model has to predict the next word in the target corpus.
- Fine-tuning In this step, the language model is fine-tuned with a classification layer for the target task (e.g., classifying the sentiment of movie reviews).
By introducing a viable framework for pretraining and transfer learning in NLP, ULMFiT provided the missing piece to make Transformers take off. In 2018, two transformers were released that combined self-attention with transfer learning:
GPT Uses only the decoder part of the Transformer architecture, and the same language modeling approach as ULMFiT. GPT was pretrained on the BookCorpus, which consists of 7,000 unpublished books from a variety of genres including Adventure, Fantasy, and Romance.
BERT Uses the encoder part of the Transformer architecture, and a special form of language modeling called masked language modeling. The objective of masked language modeling is to predict randomly masked words in a text. For example, given a sentence like “I looked at my and saw that was late.” the model needs to predict the most likely candidates for the masked words that are denoted by . BERT was pretrained on the BookCorpus and English Wikipedia.