The central challenge of ML is that our model must perform on new unseen inputs: generalize
Model capacity
This is the difference with optimization: Generalization error must be low as well
A good ML algorithm should:
- make the training error small
- make the gap beetween training and test error small
The first task correspond to underfitting, the second to overfitting
One important aspect is the ‘power’ of capacity of our model, how many functions can it fit? Too low, and the training error can’t get small, too high and the model just memorize the training set and doesn not generalize well to unseen examples.
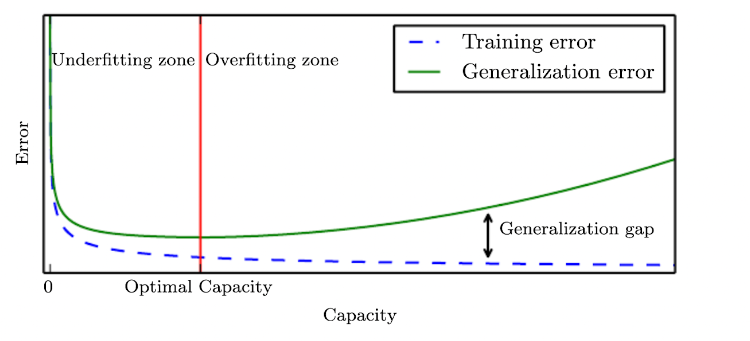 canonical graph of fitting.
canonical graph of fitting.
Regularization
This technique prevents the model from overfitting by adding extra information to it.
To achieve this, it introduces contraints on the parameters space, reducing the flexibility of the model, but keeping the same number of parameters.
For example one can penalize some values on the parameter space by adding a function of the weights in the loss:
this penalizes bigger values of the parameter vector . In the The bayesian setting this can be interpret to assume a gaussian prior on the wights.
To find one can train the model and test in on a validation set, and keep the best .