A simple algorithm for word embedding, i.e. from a simple one-hot representation we get a semantic vector of choosen size.
This is a bag of words model, it doesn’t care about word order. The idea is to choose a fixed context windows , and then train a shallow model to predict the words in the context around a given word. The hidden layer is new given word embedding.
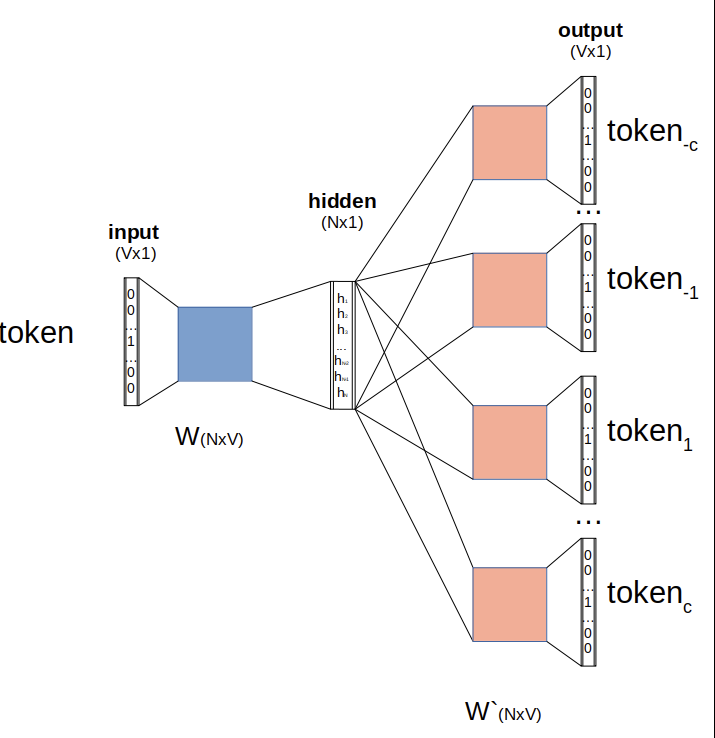
The loss is computed by summing all the predicted vectors, so as we said it doesn’t care about the order.
Huge drawback
- doesn’t care about context, homonyms have the same embedding!