Mc Culloch Pitts neuron
E’ un modello matematico semplificato dei complicati modelli differenziali dei Biological neurons. Introdotto nel 1943, chiamato anche formal neuron, in breve:
the formal neuron receives a series of inputs from adjacent neurons and generates an output that results from the sum of the inputs, each of which is weighed by a factor that takes into account the functioning of the related synapses
Assumiamo che un neurone ed i suoi neuroni vicini (collegati da sinapsi) ciascuno con uno stato possibile che insieme formano lo stato della rete , ed un insieme di pesi sinaptici , allora l’output del neurone è determinato da:
viene detta soglia di attivazione, se il potenziale presinaptico definito come:
è minore di l’uscita è nulla (quiescient state), per la funzione di Haveside, in caso contrario (active state).
Se vogliamo costruire reti collegando questi neuroni, allora l’uscita è anche l’insime degli stati, quindi . Se pensiamo ad una rete allora definiamo una matrice di interazioni , quindi per ogni neurone vale:
notiamo che possiamoa vere interazioni non simmetriche ed autointerazioni .
Universalità dei neuroni MP
Every finite digital machine can be regarded as a device that maps finite-dimensional binary input vectors (could be a partial function that doesn’t terminate!) in a finite string with the same alphabet .
Then every finite deterministic digital machine can be specified in full by specifying the output vector for every possible input vector, that is, by specifying the mapping :
Possiamo scomporre la mappa in mappe indipendenti con stesso input ma solo un bit in uscita:
We conclude that we are allowed to concentrate only on the question of whether it is possible to perform any single-output mapping M : Ω ⊆ {0, 1} N → {0, 1} with networks of MP neurons.
we first introduce a partitioning of the set of input vectors into two subsets, depending on the corresponding desired output value:
Quindi le macchine devono capire se l’input è nel sottoinsieme giusto, ovvero oppure . Chiamiamo gli elementi di che applicati ad danno in uscita il bit . Quindi quello che deve fare la rete, è dato un input controllare se , ovvero se è uguale a qualche elemento: tale che . se è così, restituisce uno, zero altrimenti. Questa cosa si può fare facilmente con operazioni binarie elementali, infatti se , sono uguali bit a bit, un and:
quindi:
Le operazioni logiche usate sono ovviamente realizzabile con delle reti di neuroni :
Osservazione
Un solo layer non può nemmeno fare tutte le operazioni binarie, non esiste per lo . Il motivo geometrico è chiari: non sono linearmente separabili!
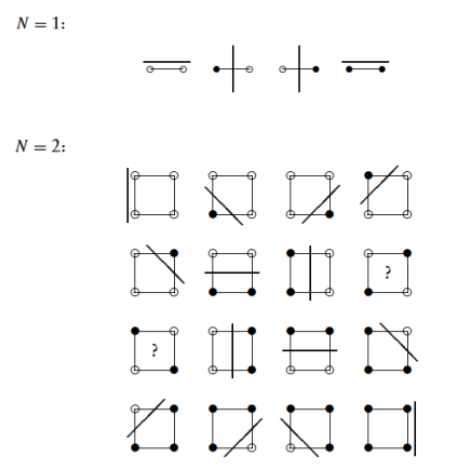
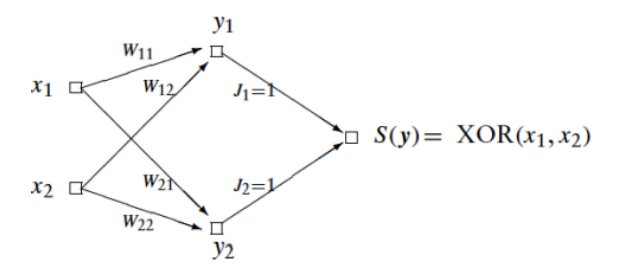
Quindi bastano due layer per replicare lo . In realtà vale il claim forte:
Teorema bastano 2 layer
Ogni funzione può essere rappresentata da una reta di solo due layer.
Proof
L’idea è molto semplice, il livello nascosto contiene un neurone per ogni configurazione dentro . Il compito di questi neuroni è accendersi se riconoscono una certa configurazione. Non ci resta quindi che mettere un singolo neurone finale di .
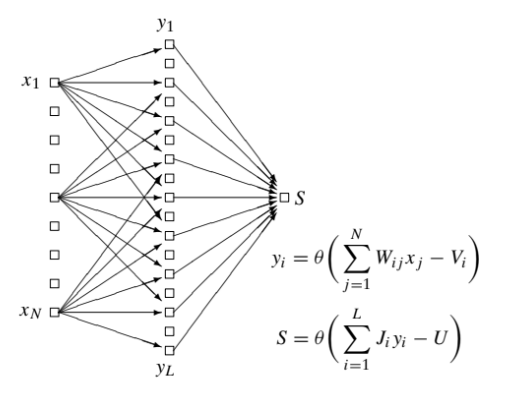
La questione è quindi costruire i neuroni dell’hidden layer. Definiamo una funzione building block con la proprietà voluta:
claim la funzione:
fa quello che voglio.
- Se
vale:
quindi
concludendo che .
- Al contrario quando , i corrispondente termini nella sommatoria valgono:
di conseguenza la somma vale:
quindi nell funzione theta ho:
perchè per ipotesi almeno un indice è divetso, quindi .
Ovviamente fissato la funzione può essere rappesentata da un neurone , basta espandere il prodotto, ho termini lineari in ed altri costanti.
La rete finale avrà dunque i parametri:
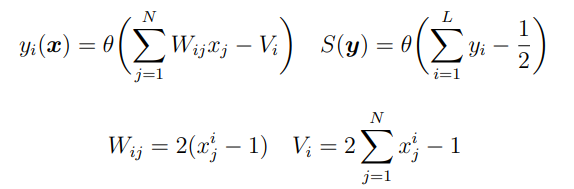
Remaks
- Il numero di neuroni necessari per il livello nascosto può scalare con le dimensioni dello spazio , ovvero è esponenziale in N ()
- concatenando le varie reti per ogni bit, otteniamo sempre una rete a due layer.
- Perfect knowledge of the function allowed us to determine the set of weights which makes the network to exactly emulate . In real situations the scenario is different: only a sample of input-output pairs is available and, based on these, we have to infer the “optimal” (according to some cost function) configuration for weights which makes the network to emulate the operation M at least on the basis of the available knowledge. In order to find this setting one introduces learning rules, namely iteractive evolution rules to tune weights.
Dinamica
Possiamo introdurre una dinamica discreta tra stati di una rete :
Si può pensare a come un tempo refrattario dei neuroni biologici.
Ci sono due maniera di realizzare questa dinamica:
- Dinamica parallela Gli stati evolvono tutti insiemi;
- Dinamica sequenziale Si sceglie un neurone e si aggiorna solo quello.
Stocasticità
Introduciamo delle perturbazioni random sulla soglia di attivazione, sommando una variabile a media nulla:
dove è la deviazione standard, una variabile a media nulla e varianza unitaria. Il parametro controlla dunque il grado di stocasticità (una temperatura).
Effettuiamo anche in cambio da a spin . La regola di update diventa:
da qui si capisce il fattore aggiunto al rumore. La quantità viene detto campo locale.
La probabilità di trovare un neurone nello stato al tempo è dunque una variabile aleatoria che dipende dalle v.a. e dallo stato della rete . Se supponiamo sia simmetrico:
esprimento il tutto in funzione della cumulativa
Con la cumulativa è ; un’altra scelta simile è la tangente iperbolica:
a cui corrisponde un rumore distribuito come:
Per la dinamica parallela, supponendo le variabili indipendenti, la probabilità fattorizza e si ottiene:
Noiseless recurrent networks
Studiamo la dinamica nel caso noiseless per i casi
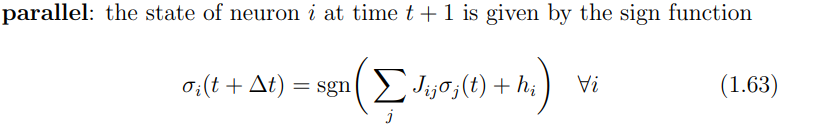

Parallel dynamics
Es 1 Caso banale: e . La regola di update è banale, non dipende dallo stato precedente, dopo una iterazione tutto il sistema va nello stato finale:
Il bacino di attrazione per questo stato punto fisso è tutto il dominio .
Es 2
Supponiamo ora e , ovvero interazioni simmetriche e campo esterno nullo.
Otteniamo la regola di update:
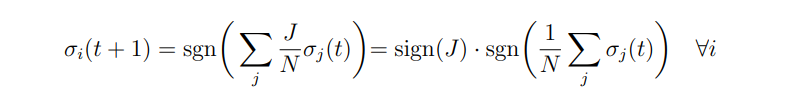 Notiamo come compare un’osservabile macroscopica, la magnetizzazzione media (spin medio):
Notiamo come compare un’osservabile macroscopica, la magnetizzazzione media (spin medio):
Possiamo ottenere una formula di update per questa osservabile macroscopica sommando:
Se , abbiamo una dinamica imitatoria: i neuroni tendono a fare quello che fanno gli altri. Partizioniamo le configurazioni in:
(supponiamo di avere un numero dispari di neuroni, così non abbiamo il caso patologico ).
Abbiamo punti fissi e che corrispondono a e .
Se abbiamo un ciclo limite di periodo due tra stati ed .
Es 3
Caso e .
La regola di update della magnetizzazzione media è:
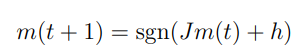
Se il campo esterno è troppo forte, ovvero otteniamo una dinamica banale, come nel caso senza interazioni.
Con otteniamo sempre due punti fissi, ma con bacini d’attrazione non uguali e che dipendono dal rapporto .
Con otteniamo sempre un ciclo di periodo due, controlla quanto ci metto a raggiungere il ciclo.
Sequential dynamics
Studiamo gli stati limite tramite Funzioni di Lyapunov.
Proposizione Se abbiamo interazioni simmetriche , ed autointerazioni non negative , un campo esterno e noisless (), allora
è una funzione di Lyapunov della dinamica sequenziale:
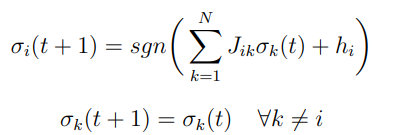
dove si estrae uniformemente in .
Durante la dinamica la funzione evolve:
Siccome è limitata inferiormente, ammette un minimo ed il sistema arriverà a queste configurazioni e si fermerà. (Richiediamo distanza di hamming ).
Pattern retrival
Possiamo vedere questa abilità delle reti di “ricordare” informazioni , dato un input iniziale , sfruttando questa dinamica verso attrattori.
Basando sulla regola (principio) di Hebb:
Neurons that fire together wire together Neurons out of sync fail to link
Risulta ragionevole:
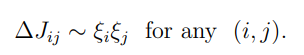 Si vede facilmente che possiamo memorizzare singoli pattern definendo le connessioni in accordo con la regola di Hebb. Aggiungere campo esterno complica le cose, valgono le stesse considerazioni fatte nella dinamica parallela caso simmetrico con campo esterno. Quindi la rete avrà punti fissi in e , a seconda di .
Si vede facilmente che possiamo memorizzare singoli pattern definendo le connessioni in accordo con la regola di Hebb. Aggiungere campo esterno complica le cose, valgono le stesse considerazioni fatte nella dinamica parallela caso simmetrico con campo esterno. Quindi la rete avrà punti fissi in e , a seconda di .
Per più pattern, una scelta ragionevole è mediare:
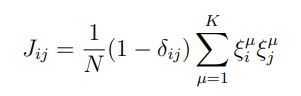 Per semplificare la trattazzione assumiamo che i pattern siano ortogonali.
Per semplificare la trattazzione assumiamo che i pattern siano ortogonali.
Proposizione La dinamica sequenziale applicata ad una rete con pesi dati dalla regola di Hebb e , mostra stati stazionari, che corrispondono ai pattern ed hai loro inversi.
Dim Scriviamo la funzione di Lyapunov:
con la regola di Hebb e campi esterni nulli
notando che
dunque
Il termine al quadrato non è altro che il prodotto scalare tra lo stato ed il pattern (normalizzato) . Siccome abbiamo supposto per ipotesi che i pattern sono ortogonali, per massimizzare il prodotto scalare deve avere la stessa direzione di , ed in questo caso e zero per gli altri pattern, dunque:
ed il minimo si ottiene quando .
Osservazione Non è vero che tutti i minimi sono pattern, esistono dei minimi spuri.
Proposizione Misture dispari dei pattern sono stati stazionari. Misture pari sono stati stazionario instabili. Sono minimi locali.
Domande
- Capacità della rete? (in funzione di )
- Training migliore?
- Utilità del random noise?